

Wilson Vega
Director
Jimmy Pepinosa
EditorGoogle LLC presentó hoy, en su evento I/O, una nueva plataforma de comunicación de video 3D que llamó Google Beam.
Impulsada por inteligencia artificial y enfocada en aplicaciones empresariales, Google Beam está diseñado para acercar la colaboración remota a la interacción en persona.

Beam es una evolución del Proyecto Starline, una iniciativa de investigación de varios años anunciada por primera vez en 2021 que tenía como objetivo redefinir las videollamadas a través de tecnologías avanzadas de IA e imágenes.
En su momento, Project Starline permitió conversaciones remotas mucho más cercanas a la experiencia real, sin la necesidad de anteojos o auriculares especializados. Beam da un paso gigantesco hacia adelante.
Lo hace al integrar un modelo de video volumétrico de IA que convierte las fuentes de video 2D en representaciones 3D realistas en tiempo real. Para eso usa seis cámaras a 60 fps y una pantalla de “campo de luz”, lo que permite a los participantes hacer contacto visual, leer señales sutiles y generar y registrar elementos de la interacción humana como si estuvieran hablando cara a cara.

Aunque más que un producto Google presentó un concepto, trascendió que los primeros productos con Google Beam serán fabricados por HP y estarán disponibles a finales de este año. También se indicó que Google cooperó con como Zoom para garantizar que Beam pueda operar dentro de los ecosistemas de comunicación empresarial más usados.
Un nuevo tipo de traducción simultánea
 (Google)
(Google)
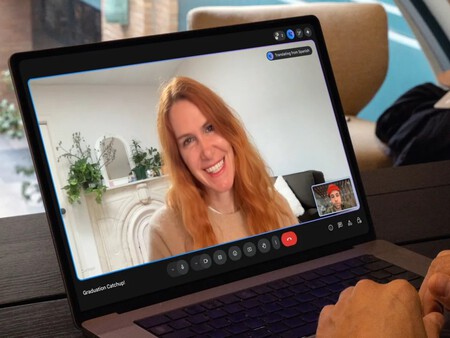
Como parte del lanzamiento, Google también está introduciendo capacidades de traducción de voz en Beam, a partir de hoy con Google Meet. La función ofrece conversaciones auténticas traducidas casi en tiempo real mientras mantiene el tono de voz y la expresión.

Esta nueva herramienta ya comenzó a llegar a los usuarios suscritos a los planes Google AI Pro y Ultra, y permite traducir lo que una persona dice durante una reunión en Meet al idioma preferido del receptor, en cuestión de segundos.
Lo distintivo de esta función es que no solo traduce el contenido hablado, sino que también conserva el tono, la cadencia y la expresión emocional del hablante original, con el fin de mantener una experiencia de conversación lo más natural posible.

Según Google, esta innovación se apoya en un modelo de audio lingüístico de última generación desarrollado por DeepMind, su laboratorio de investigación en inteligencia artificial.
Un modelo que entiende el lenguaje humano
 (Google)
(Google)
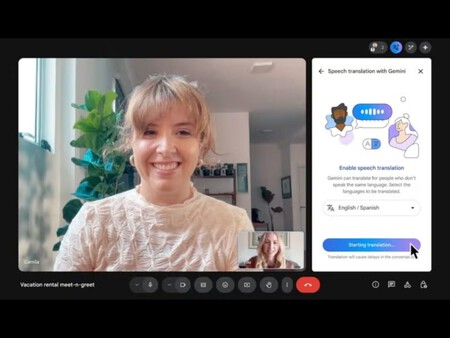
Este modelo ha sido entrenado para entender el lenguaje humano en múltiples dimensiones: desde la fonética y la entonación, hasta los matices culturales que inciden en cómo nos comunicamos oralmente.

El resultado es una herramienta capaz de generar traducciones en voz que suenan fluidas y auténticas, eliminando las interrupciones y los desajustes de tono que solían caracterizar a las traducciones automáticas tradicionales.
La función se lanza inicialmente con soporte para inglés y español, con la promesa de incorporar más idiomas en las próximas semanas. Y en esta primera fase, está disponible para usuarios individuales, pero Google ya está trabajando en una versión empresarial que será probada por organizaciones dentro del ecosistema de Workspace.

Aunque el uso potencial de esta tecnología va más allá del entorno corporativo. Desde reuniones globales de trabajo hasta conversaciones personales entre familiares que viven en distintos países y no comparten idioma, la traducción de voz en tiempo real abre una nueva posibilidad de conexión entre personas, sin necesidad de intérpretes ni de depender exclusivamente del subtitulado.